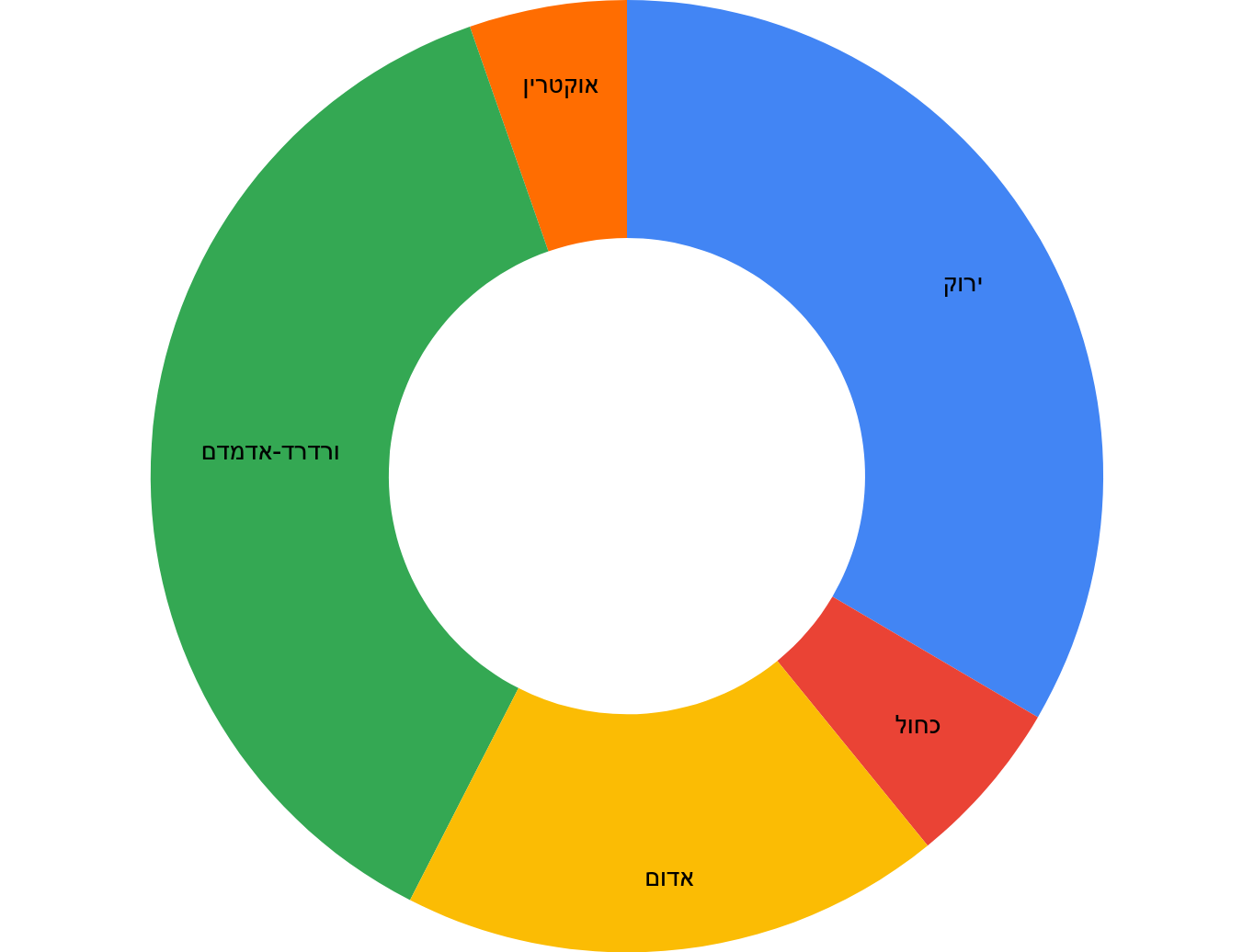
בעודי מתארגן על ארוחת ערב לילד קפצה לה איזו התראה בפייסבוק. עשרים דקות אח"כ עוד אחת, וקצת אחרי זה גם הגיע אישית בוואטסאפ, אז הבנתי שני דברים: הראשון הוא שמעריב החליטו להוציא אינפוגרפיקה מוטה באופן בוטה במיוחד, והשני הוא שאני מאד מרוצה מזה שאנשים יודעים לשלוח לי דברים כאלה כשהם רואים אותם:
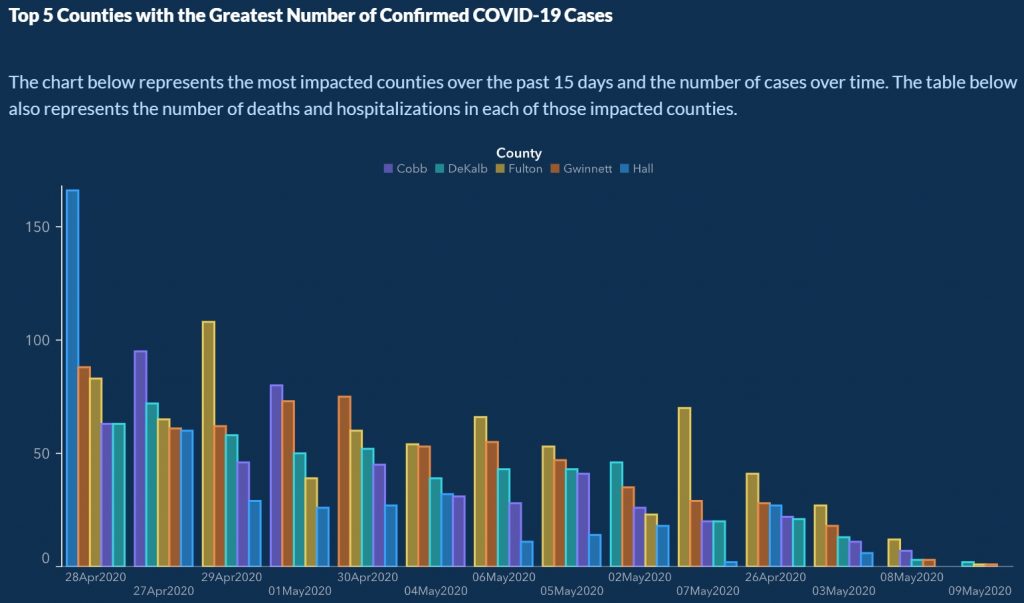
ההטיה היא ברורה ולא חדשה (גם במאקו כאן, למשל) – הנתח האדום הוא 54%, כלומר יותר מחצי, אבל פלח העוגה הוא בבירור קטן מחצי (נגיד, בערך 48%). טעות שקלה לזיהוי, אבל עדיין גורמת לכך שהמסר הויזואלי המיידי של הגרף הוא "פחות מחצי רוצים", בעוד הנתונים עומדים אחרת. לעמעם את המסר.
לשאלה האם זו הטיה מכוונת או לא קשה לי לענות. בפוסט המקושר על ההטיה של מאקו כתבתי בתגובות באופן מאד נחרץ שמדובר בהטיה מכוונת, כי אף אחד שעבד על זה לא היה יכול לפספס את הטעות הבוטה הזו. אבל מאז אני פחות נחרץ, ומאמין גדול ביכולת של אנשים לעשות את העבודה שלהם ברבע כח (בטח בשעת סגר כשהם כנראה עובדים מהבית) ולפספס משהו כ"כ בסיסי ולתת לזה לצאת. אני מכיר הרבה אנשים ממש מוכשרים ומסורים שעובדים בעיתונות בישראל, ועדיין ההתרשמות שלי, מניסיון שלי ושל אחרים, שרמת המקצועיות הממוצעת לא מאד גבוהה ורק ממשיכה לרדת, וטעויות כאלה (ובוטות הרבה יותר) יכולות בהחלט לרדת לדפוס, כפי שטוען התער של האנלון, כשטיפשות היא הסבר מספק, לא חייבים זדון.
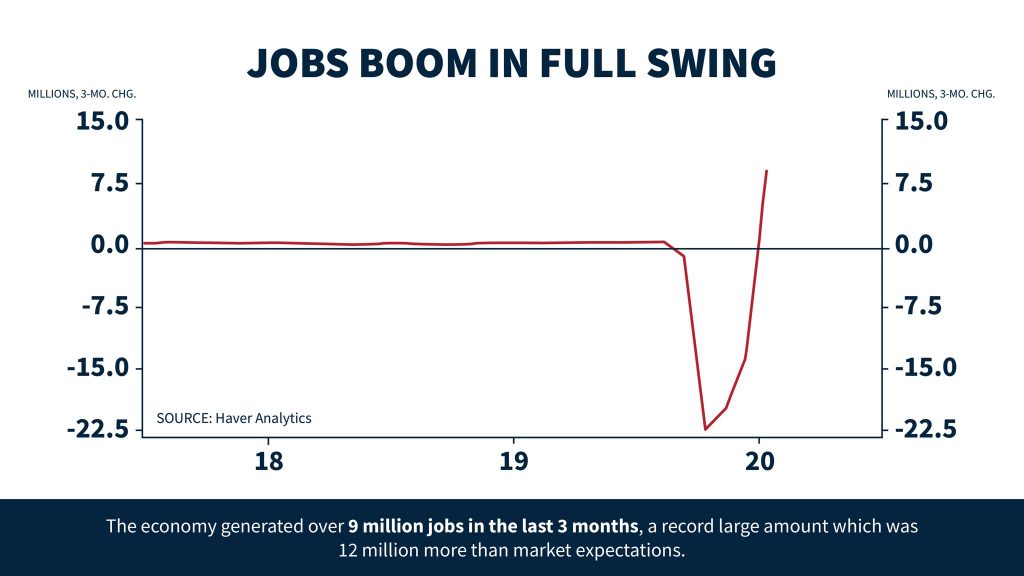
דונלד טראמפ, נשיא ארצות הברית בכבודו ובעצמו, פרסם את הגרף הזה לפני כמה ימים בחשבון הטוויטר שלו, עם הכותרת הצנועה, יחסית לטראמפ – "העליה בתעסוקה ממשיכה!". ועל פניו נראה שגרף אכן מראה עליה מרשימה בתעסוקה – 7.5 מיליון מועסקים חדשים לעומת שנת 2019! אמנם היתה ירידה בתחילה 2020, מה שברור, אבל עברנו את המשבר ויצאנו מנצחים!
מה, לא?
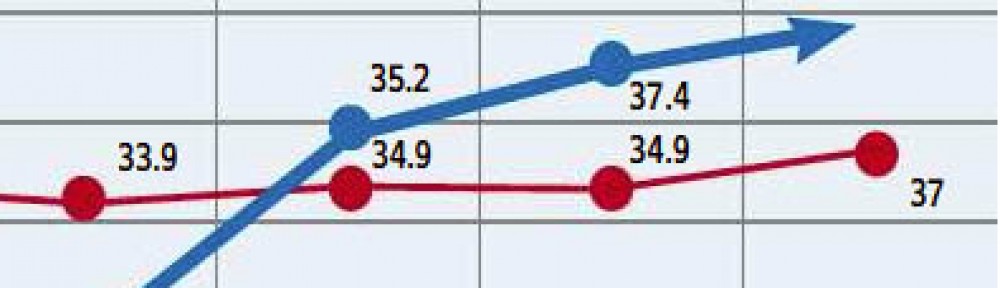
מה שאנחנו רואים כאן זה לא, כפי שאולי אפשר לחשוב בטעות, רמת האבטלה בארה"ב בשנתיים האחרונות (או, איך שהאמריקאים אוהבים לקרוא לזה, "יצירת מקומות עבודה"), אלא מראה את השינויים ביצירת מקומות עבודה בתקופה הזו, כלומר זו הנגזרת של הגרף האמיתי של סך המועסקים בתקופה הזו (ותודה ל-@eyal6699 על הניסוח המדויק)
כלומר, אם לאורך 2018 ו-2019 לא היו שינויים במספר המועסקים במשק (מה שנראה לי מוזר, אבל נעזוב את זה כרגע), אז אנחנו רואים בתחילת 2020 ירידה של עד 22.5 מיליון מקומות עבודה (כלומר, 22.5 מיליון מובטלים חדשים), ואז, באמצע השנה, עליה של 9 מיליון מקומות עבודה. אבל בניגוד לאינטואיציה, אנחנו לא נמצאים במקום גבוה יותר, אבסולוטית, משהיינו לפני הירידה של 2020 – אנחנו פשוט מראים שאחרי ירידה של 22.5 היתה עליה של 9, כלומר אנחנו עדיין במינוס 13.5 מיליון מקומות עבודה יחסית לנקודת ההתחלה שלנו.
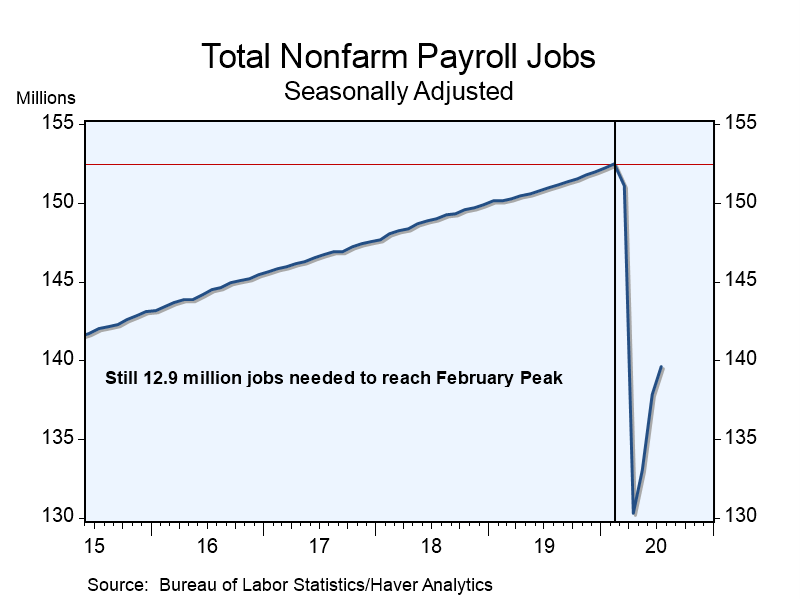
רציתי לקפוץ לאקסל ולהכין גרף עם הנתונים האבסולוטיים, אותם רציתי לקחת מהאתר של Haver Analytics שמאוזכרים בגרף המקורי. אבל לשמחתי, האתר שלהם (שנראה כאילו עוצב לאחרונה ב-1998) כבר הכיל את הגרף הזה בעצמו:
תמונה קצת שונה, נכון? ומאותם נתונים בדיוק. היא מראה התאוששות, אבל עדיין רחוק מלחזור למצב לפני פרוץ הקורונה. אבל עם הגרף של הנגזרת, הכל נראה הרבה יותר ורוד.
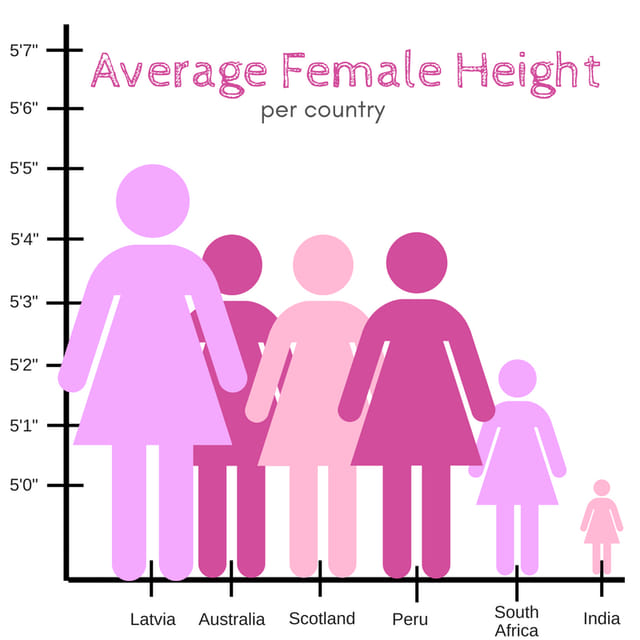
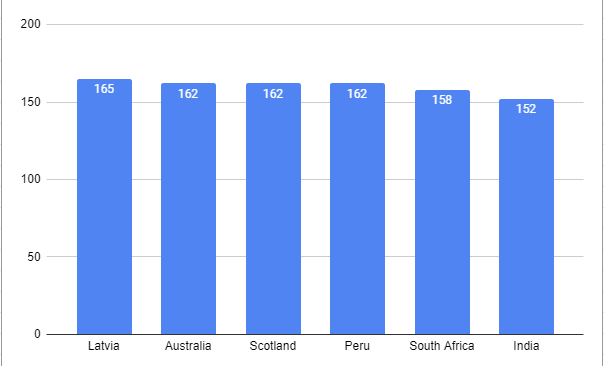
דורי, ידיד הבלוג מימים ימימה, הפנה את תשומת ליבנו לתרשים הזה שמסתובב לו באינטרנט כבר כמה שנים, שסובל מכמה בעיות די גדולות, אפילו מעבר לבחירה הקצת בנאלית לעצב גרף שקשור לנשים כשכולו בצבע ורוד.
הבעיה הראשונה שהגרף סובל ממנה הוא חביבנו הקבוע, קיצוץ בסיס מערכת הצירים. למי שעוד לא נתקל, הכוונה כאן היא שציר ה-Y לא מתחיל מ-0, אלא בעצם מגובה 5 פיט (שזה 1.52 מ'). משם והלאה המרחקים קבועים, אבל זה אומר שה"עמודה" השמאלית, שמייצגת גובה של 1.65 מ', גבוהה יותר מפי 4 מהעמודה הימנית, למרות שההפרש בין 1.52 מ' ל-1.65 מ' הוא פחות מ-10%. זה יוצר הקצנה של הפערים כשמתמקדים רק בראש מערכת הצירים.
אבל זה, בפני עצמו, לא כזה נורא. זה פשוט הסיפור של הגרף, להדגיש את ההבדלים בין מדינות שונות, וצריך גם לזכור שבחוויה האישית, הפרש של 13 ס"מ הוא מאד משמעותי. אבל כאן נכנסת הבעיה השניה של הגרף, שיחד עם הראשונה, מייצרת את הצרימה הויזואלית.
הבעיה השניה היא בחירה להחליף את העמודות הפשוטות בעמודות שמעוצבות כמו הסמליל הגנרי ל-"אישה". והבעיה עם זה היא שהסמליל הוא פרופורציונלי בין שני הממדים שלו. כלומר, כל שינוי בגובה, מחייב גם שינוי ברוחב בשביל לשמור על הפרופורציות. וזה אומר שכשאנחנו קובעים את גובה העמודה השמאלית כפי 4 מהגובה של הימנית, אנחנו גם מגדילים את הרוחב פי ארבע. ה-"עמודה" הלאטבית לא סתם גבוהה פי 4 מההודית, היא גם רחבה פי 4, ולכן גדולה, פרופורציונלית, פי 16 (וזה להפרש גובה ממוצע של כ-8%, כן?)
מעבר לזה שזה מעמיס ויזואלית על הגרף עם נשים ענקיות, זה מכניס כאן הטיה שאני אוהב ושאין לי שם טוב בשבילה, שבה כמות הפיקסלים שבה פריט מיוצג משפיע על הגודל הנתפס של הפריט, גם אם הפיקסלים הללו לא רלבנטיים לנתונים. ראינו את זה בפוסט האחרון, כשתרשים עוגה הגדיל גם את הגובה של הפלח בנוסף לשטח שלו, וגם בפוסט שלפניו על העוגה התלת-ממדית, וההטיה שהיא מייצרת בתפיסה החזותית שלנו. יותר פיקסלים, יותר חשיבות, גם אם הנתונים לא תומכים בזה.
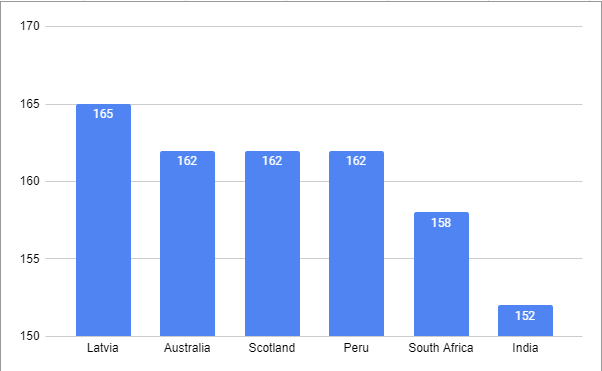
ולסיום, דוגמה לאיך הגרף היה יכול להראות בלי הבחירה הזו. זו גם הזדמנות טובה איך הגרף יכול להראות כשמורידים את קיצוץ בסיס מערכת הצירים ולראות עד כמה הוא… לא מועיל, לא מעביר מידע ולא מספר סיפור:
וגם אותו הגרף כשאנחנו כן תוחמים את התצוגה לטווח הממוקד בין 1.50 ל-1.70, ומקבלים סיפור אחר, אולי מעניין יותר, אולי מוקצן יותר, אבל פחות מבלבל ויזואלית מאותן נשים ענקיות.
רק עברו כמה ימים מאז שכתבתי פוסט על הסכנות וההטעיות בעוגות תלת מימדיות, והנה התפרסם בבלוג Junk Charts של קייזר פונג (שהוא במידה רבה ההשראה לבלוג הזה) דוגמה קיצונית אפילו יותר:
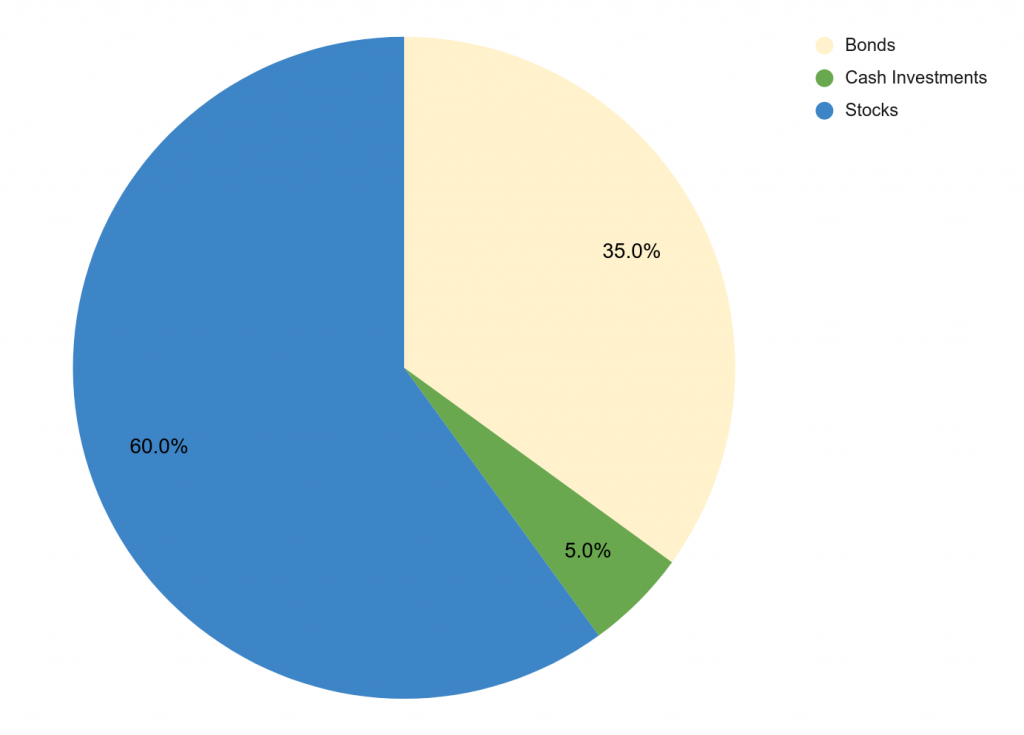
בגרף הזה, מבית ההשקעות צ'ארלס שוואב, מציג נתונים פשוטים. באמת, באמת פשוטים. הנה הנתונים הללו בעוגה פשוטה:
לא מסובך, נכון? שלושה פלחים, בלי יותר מדי תחכום. אבל מישהו בצ'ארלס שוואב החליט להתחכם, והפך את העוגה לתלת מימדית. אבל בניגוד לעוגה התלת-מימדית מהפוסט הקודם, שם הנפח של העוגה מוסיף משקל אקראי לפלג שבמקרה בקדמת הגרף, כאן מדובר בניפוח של פלחים ביחס ישר לנתון שלהם, מה שאומר שבעצם היחס בין פלחים מוקצן ומועצם – אם 60% הוא קצת פחות מפי 2 מ-35, אז בגרף מנופח כזה, הנפח של הפלח הזה הוא הרבה יותר מפי 2 מהמקום השני.
בחישוב מהיר וגס, בעוגה שטוחה היחס בין 35% ל-60% הוא 1.71. אבל בעוגה מנופחת, אז הפלח הגדול הוא מתוך עוגה שהיא, בסה"כ שלה, גדולה פי 1.71 מהעוגה של המקום השני. כלומר אם אני מחשב נכון (ואתם מוזמנים לתקן אותי), מדובר כאן בפלח כחול שהנפח שלו הוא פי (1.71*1.71, כלומר) 2.94 מהנפח של הפלח הבא בתור (שהוא 35% מתוך עוגה שנפחה הכולל הוא קטן יותר מהעוגה הכחולה). מיחס של קצת יותר מפי 2, הגענו ליחס של כמעט פי 3.
אז אם נחזור למנטרה שלנו – מה הבחירה האינפוגרפית הזו עושה? איזה סיפור היא מעבירה? הסיפור שהיא מעבירה הוא של הקצנת הפערים. בדומה לקיצוץ בסיס מערכת הצירים, זו בחירה (מודעת או שלא) שלוקחת את הנתונים הגולמיים ומספרת סיפור שמקצין את ההבדלים בין הנתונים, בניגוד לסיפור שמטשטש את ההבדלים. האם זה ברור מהגרף שזה מה שהוא עושה? לא, אני לא חושב שזה מוצהר במפורש. וזה מה שהופך את הגרף, במודע או שלא,למניפולטיבי.
למה זה מצחיק אותי? כי יש לצערי יותר מדי אינפוגרפיקות שחוטאות ל-form over function, כלומר שמתמקדות בסגנון גם על חשבון האפקטיביות של האינפוגרפיקה, לפעמים במחיר אובדן כמעט מוחלט של היכולת להבין את הנתונים שמוצגים. עמדתי עכשיו לקשר לכמה דוגמאות ישנות בבלוג שאני מביא תמיד בהרצאות, אבל גיליתי להפתעתי שאלו דוגמאות שלא באמת העלאתי לבלוג בשום שלב, אז הגיע הזמן לתקן את החסר.
העוגה הגדולה מסך חלקיה
בפוסט ישן בבלוג הסטטיסטיקה "נסיכת המדעים", מציג יוסי לוי כמה מהבעיות של pie charts, מהגרפים הפופולריים ביותר, אבל גם הנתונים ביותר למניפולציות. אחת הדוגמאות שם שמטה לי לחלוטין את הלסת כשהבנתי אותה, והבנתי כמה קל להטעות עם גרף עוגה, ובעיקר כמה קל להטעות בטעות עם הכלים הנוחים שיש לנו היום.
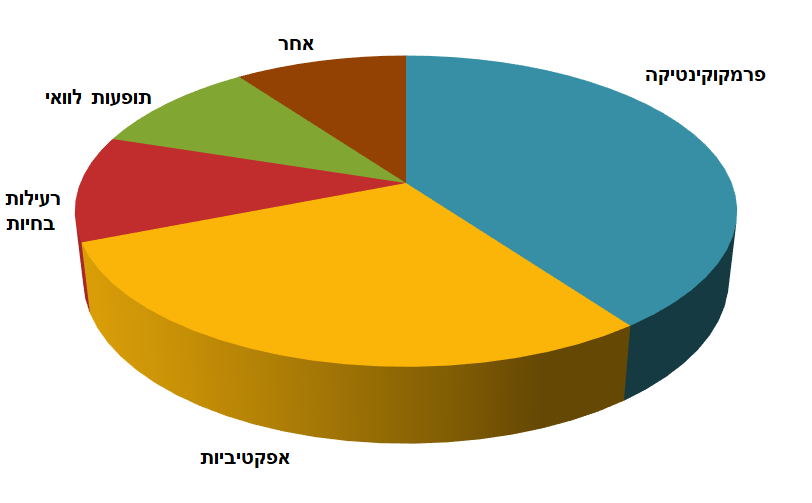
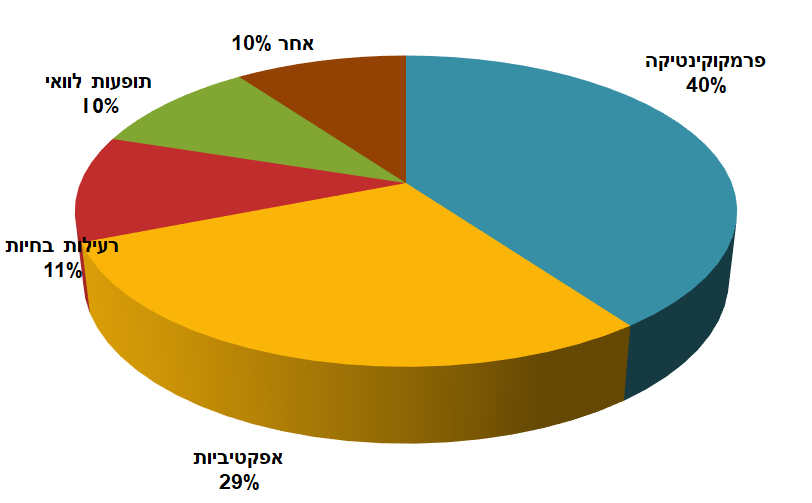
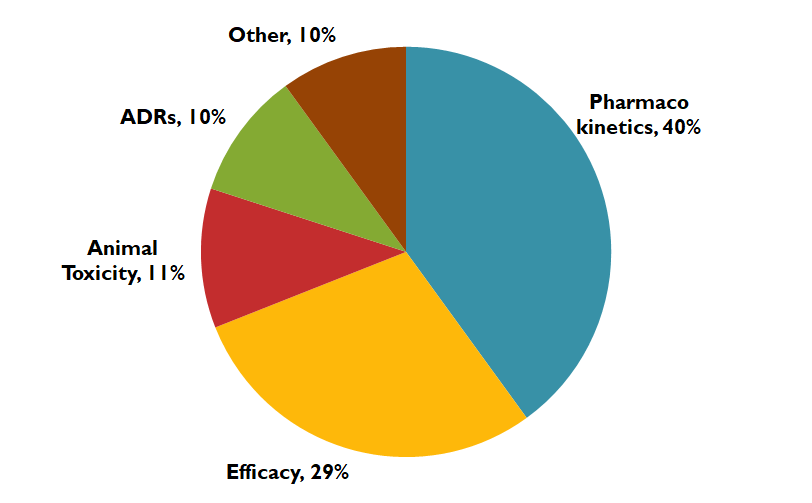
יוסי מביא מחקר שהתפרסם בכתב עת מדעי, ומציג התפלגות של סיבות לכשלונן של תרופות בשלב הפיתוח. הסריקה באיכות נמוכה, אז בניתי מחדש באקסל את הגרף כפי שהתפרסם, ואותו אני אוהב להציג לאנשים בלי המספרים המפורשים ולראות מה הם מבינים על היחס בין שתי הסיבות הראשיות – פרמקוקינטיקה ואפקטיביות של התרופה:
ברוב המקרים אנשים יגידו שהערכים שלהם די דומים אחד לשני (חוץ מהמתחכמים שמבינים שאני חותר למשהו). ואז די מופתעים כשאני שולף את המספרים האמיתיים:
הפרש של 11%! פרמקוקינטיקה מובילה במעל 50% מעל האפקטיביות? איך יתכן פער כזה בגרף שלא משקר במכוון (ואני ייצרתי אותו באקסל ישירות מהנתונים, בלי funny business)?
הסוג הוא בעיצוב ה-"נוצץ" (יחסית, כן? זה עדיין אקסל, ועוד אקסל די ישן) וההשלכה התלת-ממדית שהוא נותן לגרף העוגה הזה. הבעיה שלנו היא שה-"עומק" של הגרף, הממד השלישי, הוא לא באמת חלק מחלוקת העוגה. האחוזים מתפלגים רק בשני ממדים, והממד השלישי הוא רק ליופי. אבל העין שלנו עדיין רואה אותו. והצהוב הדקורטיבי של העומק של העוגה מצטרף לנו בעין לקידוד של הנתונים כצבע, ואנחנו רואים בערך אותה כמות טורקיז וצהוב מול העיניים. איך אפשר לראות את זה בפעולה? אקסל מאפשר לך לסובב את העוגה שהוא מצייר, ולשים פלח אחר בחזית. תראו איך זה נראה כשפרמקוקינטיקה, כ-40% מהנתונים, מקבלת גם את קדמת הבמה:
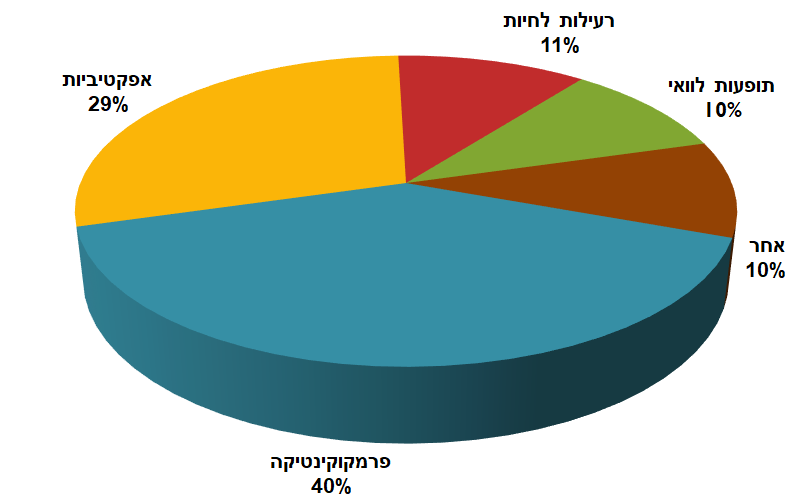
כאן כבר ברור שזו הסיבה המובילה באופן מובהק – מרגיש כאילו יש המון טורקיז. ובאמת יש. ואם ננתח את הגרף הוא גם לא משקר – 40% זה פחות מחצי ודי בבירור הוא מקבל פחות מחצי. 29% זה קצת יותר מרבע ובאמת יש קצת יותר מרבע עוגה בצהוב. אבל האפקט הויזואלי של השוליים מתווסף לנו להערכה האינטואטיבית של הגרפיקה. הנה, ככה אותו הגרף נראה בדו-ממד:
אותם נתונים. אותם צבעים. אותו גרף – אבל בלי הבלבול החזותי שהממד השלישי, העומק, מוסיף לנו. אפשר לראות שהפרמקוקינטיקה גדולה מהאפקטיביות, אבל לא בצורה כ"כ מוחלטת כמו קודם.
אבל תלת-ממד זה נראה יפה יותר, לא? ממלא יותר נפח בעמוד. מתקדם. חדשני. מודרני. אבל מבלבל. מטשטש. מיותר. אבל קל מאד להשתמש בו הישר מתוך אקסל וכלים אחרים, בלי לחשוב בכלל שבבחירה בין 2D ל-3D אנחנו יכולים לשנות את המסר של הגרף שלנו.
לפעמים אני מרגיש שצריך להזכיר למעצבי אינפוגרפיקות שבחירת הצבעים לגרפים שלהם היא שלב חשוב בבניית האינפוגרפיקה. לא כדאי להסתפק במה שאקסל מייצר לנו, אבל במקביל גם חשוב לא ללכת פשוט על פאלטת צבעים נעימה והרמונית. הצבעים של הגרף הם חלק מהסיפור שהגרף צריך לספר, ולשים צבעים שמתעלמים מזה – או גרוע יותר, שמטשטשים את זה – חטא לאפקט שאפשר לקבל.
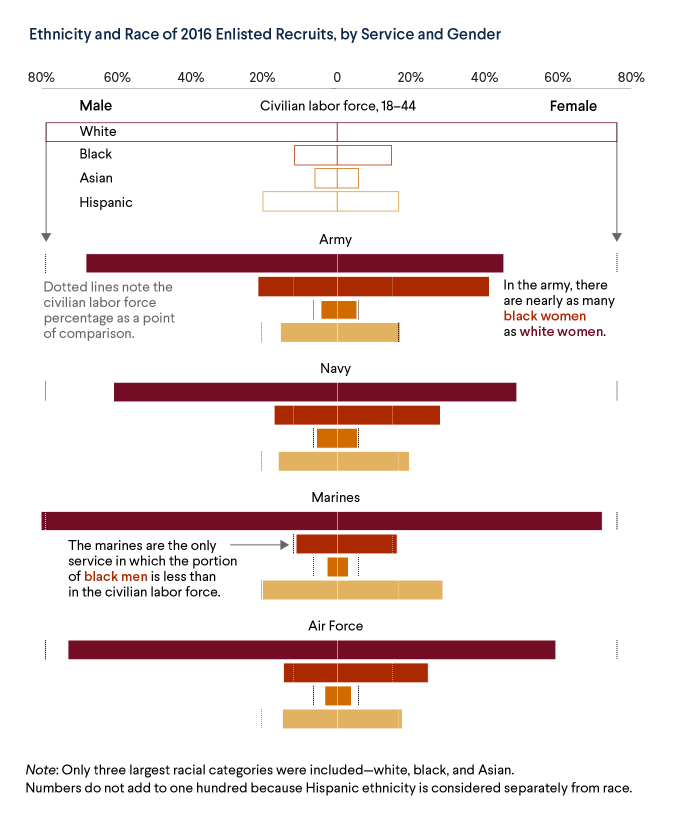
מה הבעיה שלי עם הגרף הזה, חוץ מהעובדה שבניסיונו להיות קומפקטי ויעיל הוא יוצא קצת מבלבל (צד ימין של הגרף מדבר על נשים, השמאלי על גברים, וזה לא הכי ברור)? מה שמבלבל הוא הצבעיה שנבחרו להיסטוגרמות, צבעים שדומים, במידה מסוימת, לצבעי העור של הקבוצות האתניות והגזעיות שעליהן הגרף מדבר. אבל הצבעים לא *מותאמים* לאותו צבע עור! השורה הראשונה, בצבע חום כהה, היא של שיעור הלבנים שמשרתים, בעוד השניה, בחום בהיר יותר, מתארת שחורים. אסייתים (באופן כללי) הם החום-כתום השלישי, ואז השורה האחרונה, הבז' הבהיר יותר, מתייחסת לחיילים ממוצא היספני (שיכולים בתורם להיות או לבנים או שחורים, בנוסף, אבל זה פחות רלבנטי).
יכול להיות ערך בהתאמת הצבע לאופי הנתונים. נגיד, אם מדברים על התפלגות של צבעים – הייתם יכולים
לדמיין גרף כזה? – אבל במקרה הזה, של התפלגות אתנית וגזעית, אתה נכנס לשדה מוקשים מיותר לחלוטין. איזה גוון תבחר לייצג לבנים? ואיזה שחורים? ואיזה היספנים, שכאמור יכולים להיות בכל אחת מהאפשרויות הללו? אתה לא תצא מזה, ולכן עדיף לא להכנס – עדיף היה כבר לבחור צבעים ברורים ומופרדים יותר, שלא נכנסים לספקטרום של העור האנושי – ירוקים, כחולים, סגולים – ולהמנע מזה בכלל, במקום לשים צבעים מבלבלים שלא תורמים כלום להבנת הגרף.
איפה דווקא כן יש שימוש טוב בבחירת הצבעים – או במקרה הזה, העיצוב הפנימי – של הגרף? בתרשים הזה של ה-BBC שמשווה בין התמותה מקורונה בבריטניה, לעומת זו של שאר אירופה:
גרף פשוט שמשווה שני נתונים פשוטים, אבל הבחירה להעמיס את כל דגלי אירופה על העמודה הימנית היא בחירה מאד אפקטיבית, לדעתי. היא גורמת להשוואה להיות פחות "נייטרלית" – מספר א' מול מספר ב' – ומדגישה שבצד הימני יש המון, המון, *המון* מדינות. 27 מדינות, שביחד התמותה בהם נמוכה מהמספר השמאלי.
האם זה מניפולטיבי? כמובן. חסר כאן הרבה מידע, נירמול לאוכלוסיה והרבה דברים אחרים. אבל הגרף הזה בא, במפורש, לתת את ההשוואה *הזו*, והשימוש בדגלים כאן תרם הרבה לסיפור שהוא בא לספר.
לא כל יום אני יכול להגיד שנתקלתי בשני גרפים שונים שהוציאו ממני תגובה פיזית לא רצונית ומלמול של "מה לעזאזל?!". אבל אתמול בהחלט היה יום כזה, בזכות הגרפים ששלחו לי הדס ושי (תודה, הדס ושי!), גרפים שמראים באמת עד כמה נמוך אפשר לרדת עם התעלמות מוחלטת – או, אולי, מכוונת – מאחד המרכיבים הבסיסיים בכל גרף, והוא מערכת הצירים. בפוסט הזה נתמקד בגרף הראשון שמתעלם באלגנטיות מציר ה-Y, ובמקביל יתפרסם פוסט נוסף על התעלמות מציר ה-X.
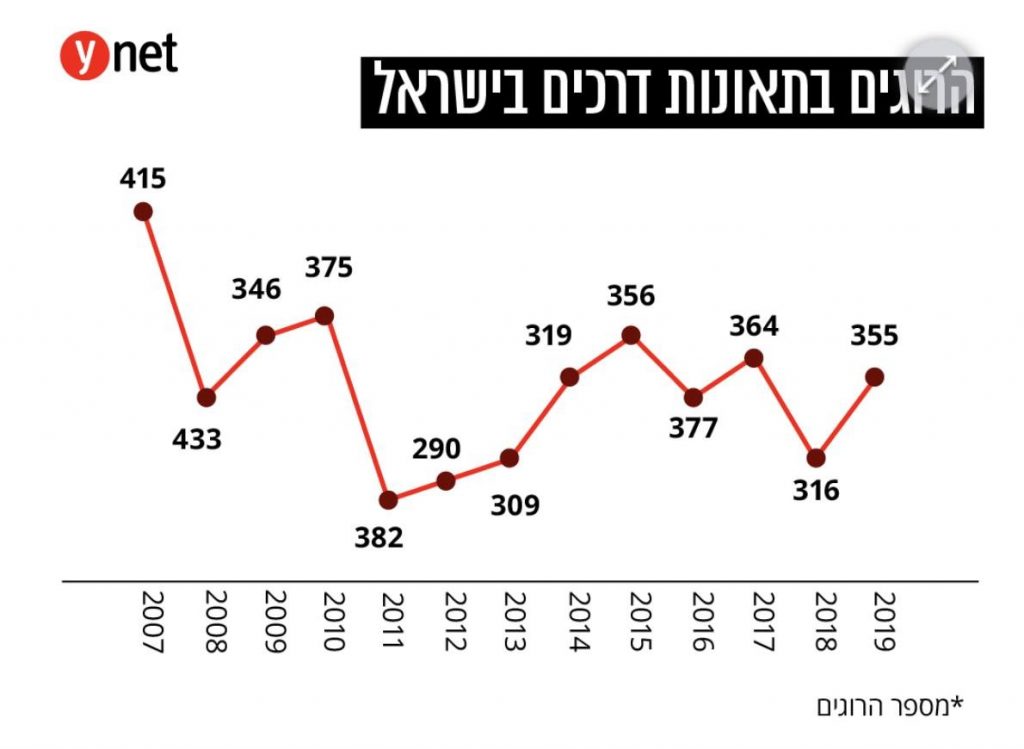
הגרף הזה פורסם ב-Ynet, בתוך כתבה ארוכה על בצלאל סמוטריץ', שר התחבורה היוצא, ופועלו במשרד. הכתבה לוותה באינפוגרפיקה הזו, אם אפשר לקרוא לה ככה, ואני בטוח שתוכלו בקלות להבין מה הבעיה איתה:
הרמז הראשון שעומדת להיות בעיה היא שבניגוד לציר ה-X (השנים), לא מסומן ציר Y על הגרף. אבל זה לא נורא, נכון? הרבה פעמים ציר ה-Y הוא implicit וקל להבין אותו מהנתונים. מה… רגע. מה קורה פה? אנחנו מתחילים ב-415, אבל אז יורדים ל-433. אולי ציר ה-Y יורד, משום מה? לא, זה לא הגיוני, כי אחרי שעלינו חזרה ל-346 (שנמצא בין 415 ל-433 מבחינת הגובה), אנחנו עולים ל-375. כלומר אין שום קשר בין העליות והירידות של הגרף לבין הנתונים שמוצגים בו. המספר הגבוה ביותר הוא 433, אבל הוא בערך האמצעי מבחינת הגובה בגרף. הנקודה הנמוכה ביותר, זו של 382, היא בין הגבוהות ביותר מבחינת הנתון. מה קורה כאן?
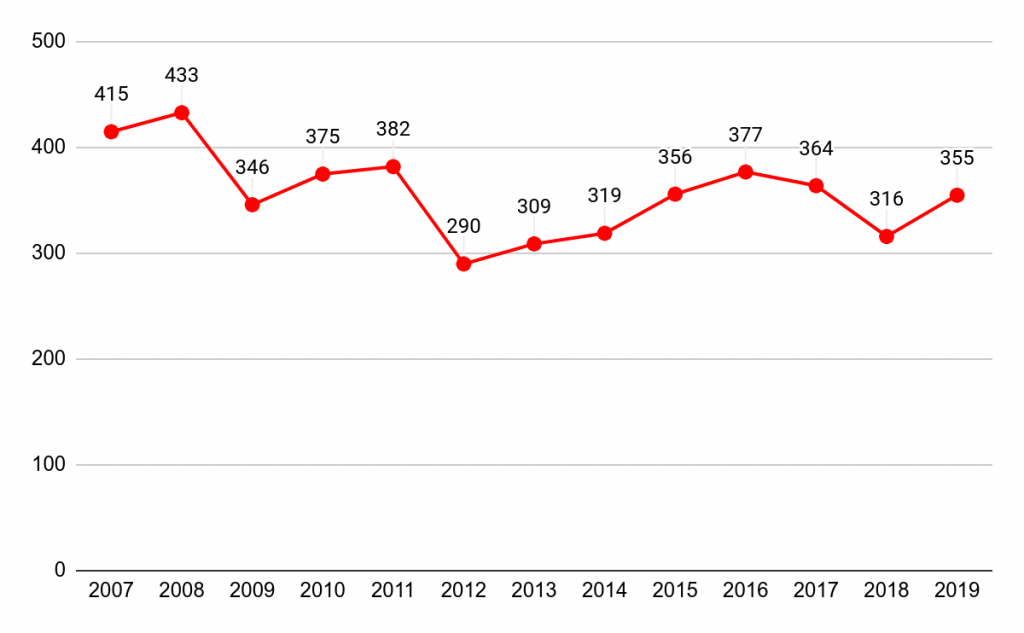
אז פניתי לחברי הטוב אקסל (או, לשם הדיוק, חברי הטוב החדש Google Sheets, פשוט בגלל שהמחשב החדש שלי מריץ לינוקס ואין לי אופיס), וזה מה שהנתונים יצרו לי:
גרף שטוח בהרבה, פחות דרמטי, ועם עליות וירידות במקומות הנכונים(!). זה גרף הרבה פחות מעניין, אפילו אם היינו מקצצים את בסיס ציר ה-Y. אבל המשכתי לתהות מה היה יכול לגרום ל-ynet לפרסם את הגרף הזה. אבל אז, אחרי קצת משחקים עם הפרמטרים של הגרף, הגעתי למשהו מעניין:
היי, מה זה פה? יש כאן את הצורה של הגרף של ynet, פחות או יותר! אולי הגרף כן הגיע מהנתונים, למרות הכל? מה קורה פה?
אז מה שקרה הוא שאני הגדרתי לגרף שציר ה-Y לא יהיה לינארי, אלא לוגריתמי. כלומר שבמקום להראות שינויים פשוטים במס' המתים בתאונות דרכים, הפכו אותו לגרף שמראה שינויים בקצב העליה או הירידה בתמותה. הבעיה היא שבניגוד לגרף הידבקות בקורונה, שאליו קישרתי כאן בתחילת הפיסקה, אין הגיון בגרף לוגריתמי אם אין לנו רצון להציג איך הקצב משתנה. זה חשוב כדי לעקוב אחרי התפשטות של מגיפה. פחות בשביל נתון עם תנודות קטנות יחסית ולא מצטברות, כמו תאונות דרכים.
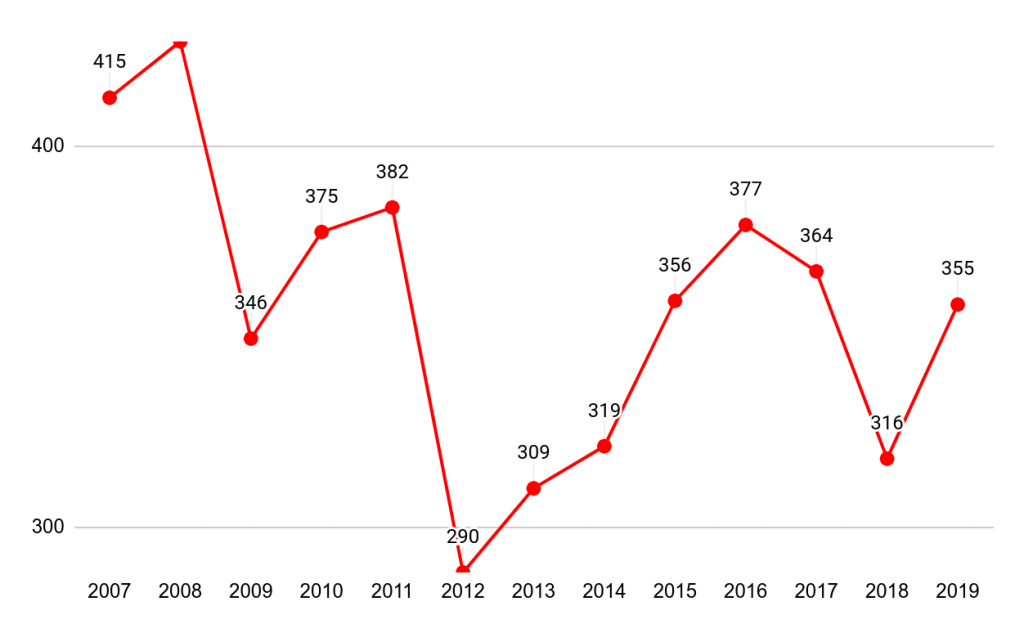
אבל זה רק מסביר איך אפשר להגיע מהנתונים לצורה הזו של הגרף. איך זה מסביר את הירידות במקום העליות? ובכן, ככל הנראה מה שקרה הוא שבגרף של ויינט פשוט קיצצו, באגביות, נתונים שלא התאימו להם, והזיזו נתונים אחרים למקום שלהם בגרף. נקודת ההתחלה של ויינט? הגבוהה ביותר בגרף? היא מתאימה דווקא ל-datapoint השני, זה של 2008, שבו באמת היה את מס' ההרוגים הגבוה ביותר (ושבגרף שלי משום מה קוצץ בשולי הגרף, אבל לא נורא, עדיין מובן). אבל כנראה שהעורך היה מעוניין בגרף שמתחיל הכי גבוה שלו ומשם יורד, בין אם על מנת להעביר מסר מסוים, או כי זה נראה טוב יותר. בכל מקרה, זה גרם לכל הגרף לזוז הצידה על ציר ה-X, ולכל הנתונים להיות מפוספסים לחלוטין. אבל אם אנחנו מניחים שיש עוד נקודה מצד שמאל שבה מתחילים הנתונים, פתאום הכל יותר הגיוני. העליה מ-346 ל-375 היא מה שבגרף כתוב מ-433 ל-346. ואז יש לנו ירידה מתונה יותר ל-382 (הגיוני!), צניחה ל-290 – הכל פתאום מסתדר הרבה יותר טוב.
ומה לגבי ynet? אני לא יודע אם השינוי הזה נעשה בכוונה או בטעות, מתוך מטרה להטעות או חוסר הבנה של הכלי. מה שאני יודע הוא ש-24 שעות אחרי שראיתי את הגרף, הוא כבר לא נמצא בכתבה. הוא לא הוחלף בגרף טוב יותר. הוא פשוט כבר לא שם.
לא כל יום אני יכול להגיד שנתקלתי בשני גרפים שונים שהוציאו ממני תגובה פיזית לא רצונית ומלמול של "מה לעזאזל?!". אבל אתמול בהחלט היה יום כזה, בזכות הגרפים ששלחו לי הדס ושי (תודה, הדס ושי!), גרפים שמראים באמת עד כמה נמוך אפשר לרדת עם התעלמות מוחלטת – או, אולי, מכוונת – מאחד המרכיבים הבסיסיים בכל גרף, והוא מערכת הצירים. בפוסט הזה נתמקד בגרף הראשון שמתעלם באלגנטיות מציר ה-X, ובמקביל יתפרסם פוסט נוסף על התעלמות מציר ה-Y.
עדכון: משרדו של מושל ג'ורג'יה, דרך מנהלת התקשורת שלו קנדיס ברוס, פרסם התנצלות על הגרף שבמידה מסוימת גרועה כמו הטעות עצמה, או לכל הפחות מעידה על כך שלא היתה כאן טעות, אלא הטיה מכוונת שפשוט התפוצצה להם בפרצוף. האם זה יגרום להם, ולאחרים, להמנע בכך בעתיד? לא הייתי שם על זה כסף.
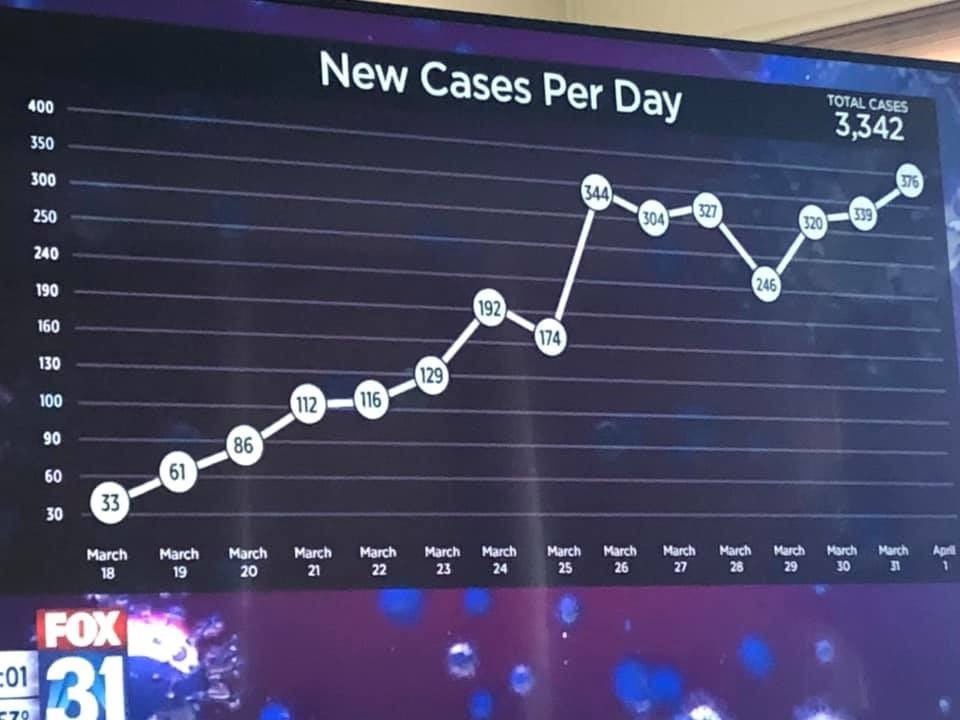
הגרף הזה פורסם באתר של משרד בריאות הציבור של מדינה ג'ורג'יה שבארצות הברית, ובא להציג… משהו שנוגע להיקף ההידבקויות בקורונה במחוזות השונים במדינה:
מה אנחנו רואים כאן, במבט ראשון? גרף די פשוט, ישיר מאד, שמסודר על ציר X של זמן וציר Y שפוי לגמרי, ללא קיצוץ מערכת הצירים. והוא מספר סיפור – כי זה הרי מה שאינפוגרפיקה עושה, לא? – סיפור ברור, ובריא, ויפה של החלמה וצמצום המגיפה.
רגע. האם זה באמת מה שכתוב שם? התעמקות קצרה בתוויות של ציר ה-X מראה לנו סיפור אחר. אחר לגמרי. ושאין שום דרך להצדיק אותו כטעות – בניגוד לכל הגיון אינפוגרפי או אחר, ציר ה-X לא מסודר לפני סדר כרונולוגי. כן, זה נכון. גרף שמציג נתונים על ציר זמן, אבל לא מסודר ע"פ ציר הזמן.
כתמיד, חשוב לחזור לשאלה הבסיסית – למה? למה הציגו לנו ככה את הנתונים? איך קרה שגרף כזה… קרה? וכאן יש כמה אפשרויות. הראשונה היא רשלנות בסיסית – אם הנתונים הוזנו, מראש, בטבלת האקסל (או google sheets, בסדר) שלא בסדר כרונולוגי, ואז הגרף נוצר אוטומטית מהנתונים כפי שהם, אז אולי היה מתקבל תוצר כזה. אולי. אבל זה עוד היה צריך לעבור דרך עיניים של גרפיקאי, של עורך תוכן. מישהו היה אמור לשים לב.
אפשרות נוספת היא פוליטית יותר. ג'ורג'יה היא אחת המדינות הבולטות בסיקור של מאבקי הקורונה בארה"ב, בין השאר בגלל ההתעקשות של הממשל הרפובליקני לחזור לפעילות כלכלית מלאה למרות אזהרות על הגברות ההידבקויות. בהקשר הזה, אפשר להסתכל על הגרף הזה כניסיון להראות מגמת שיפור מדהימה – ממצב של המון נדבקים, הגענו למצב של כמעט כלום. ניצחון! יש trend line ברור של התקדמות!
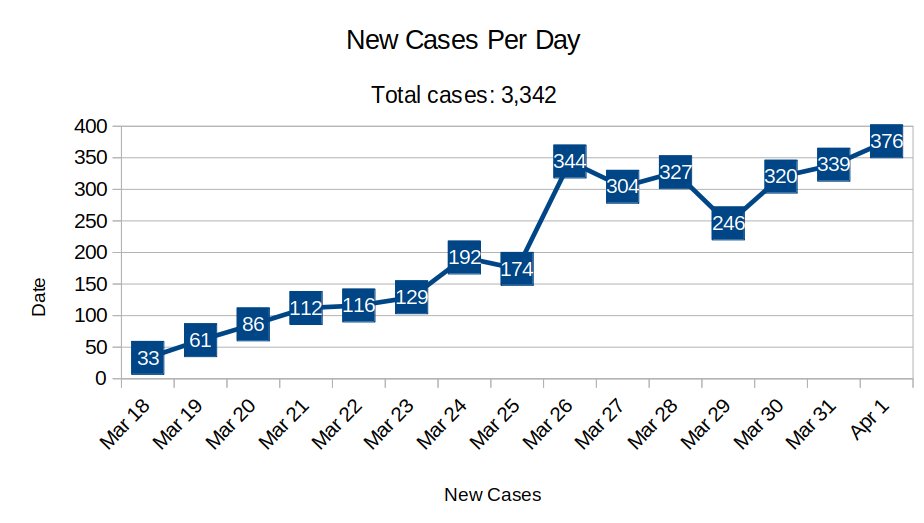
ישבתי חמש דקות עם MSPaint בשביל לסדר מחדש את העמודות בגרף, וקיבלתי משהו מוזר. הסיפור שהוא מספר הרבה פחות מובהק – אין כאן קו יורד ברור, אלא התחלה שקטה, זינוק, ירידה, ואז עליה מחדש (גל שני?) ואחריו ירידה.
אותם נתונים בדיוק, רק מסודרים ע"פ סדר כרונולוגי. אבל מה שמוזר לי הוא שהימים האחרונים בגרף הם עדיין מאד נמוכים (והם גם היו במיקום הנכון שלהם בגרף המקורי), מה שאומר שעדיין אפשר להסתכל על הגרף כסיפור הצלחה – אבל לא מובהק כמו שהיה קודם. בטח ובטח כשמדובר על שינויים לא קטנים בהפרש של שבועיים בלבד, מה שיכול להוריד את הביטחון של האזרחים בסיפור שמספרים לו.
וזה עוד לפני שדיברנו על התיאור של הגרף, שמתיימר להציג "מס' המקרים לאורך זמן", אבל גם "מס' מקרי המוות והאישפוזים". איפה כל אלה נכנסים לגרף? מה בעצם אומר המספר שאנחנו רואים? ובכן, זה סיפור אחר, ויסופר בפעם אחרת (או שלא).
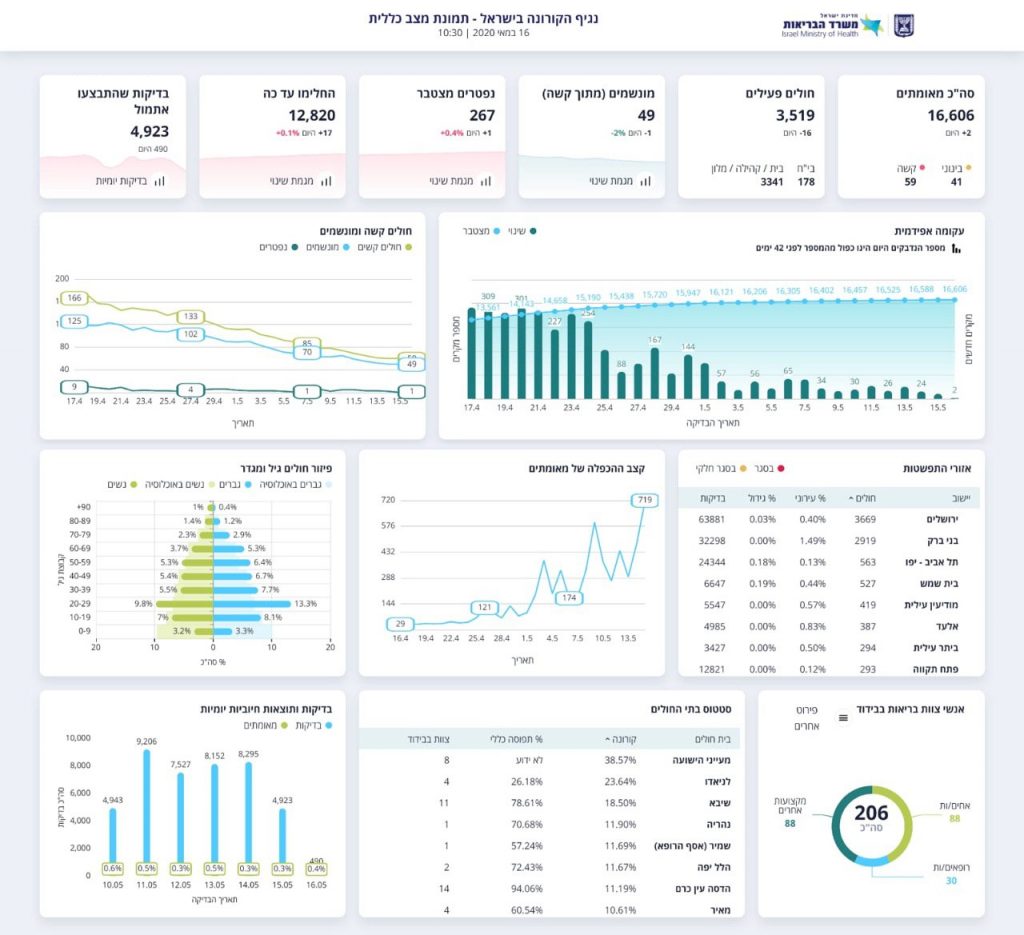
בחודשים האחרונים, משרד הבריאות מצא את עצמו במרכז תשומת הלב התקשורתית, ובין השאר, מצא את עצמו אחראי על אינפוגרפיקות עם תפוצה חסרת תקדים ברשתות החברתיות, כשלחץ הקורונה שולח את כולם להתעמק בכל גרף הידבקויות או תוחלת הכפלת נדבקים. אבל בשבועות הראשונים, היכולות של המשרד בתחום של תקשורת ציבורית, ובפרט באינגפוגרפיקה, היתה… מוגבלת. בסיסית. בעייתית.
אבל אני שמח שאחרי חודש וקצת של עבודה, התוצרים של המשרד נהיו הרבה יותר מוצלחים ומלוטשים, בלי הבעיות שהיו בהתחלה של כיווני טקסט הפוכים, הסברים שחרגו מהמסגרות ופונטים בלתי קריאים, ועכשיו אפשר לדבר עליהם עניינית יותר, על האספקטים האינפוגרפיים של העדכונים שלהם. יש לי כמה דברים להגיד עליהם, אבל בשביל לשמור על מסרים חדים יותר, אני אקדיש פוסט נפרד לכל אחד.
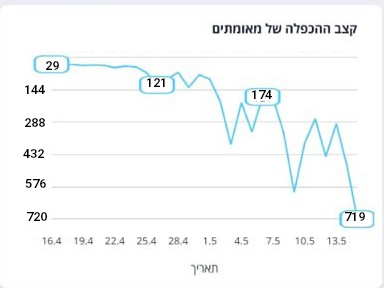
בפוסט הזה אני אתמקד בגרף שבמרכז העדכון הזה, גרף הקו שכותרתו "קצב ההכפלה של מאומתים":
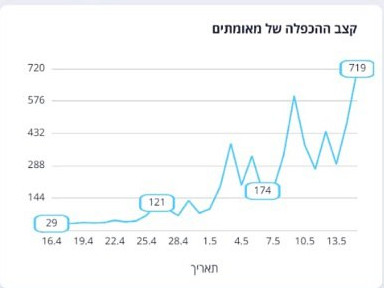
מה הכותרת אומרת לנו? שיש לנו גרף של קצב. קצב זה המהירות שבו משהו מחזורי קורה, וקצב גבוה – בין אם במוזיקה, בתקשורת נתונים, בקצב לב – הוא כשמשהו קורה מהר, נכון? זו הקריאה שלי, ואני חושב שהיא סבירה לרוב מי שיקרא את הגרף הזה.
אבל זה לא מה שהגרף בעצם מראה. הנתון המספרי הבסיסי שמוצג כאן הוא מספר הימים הדרושים כדי שמס' החולים המאומתים יכפיל את עצמו.כלומר, בנקודת ההתחלה של הגרף הערך הוא 29, כלומר מס' החולים יכפיל את עצמו בערך כל חודש. אבל בנקודה שבה לקחתי את התמונה הוא עומד על 719 – כלומר שיקח כמעט שנתיים להכפיל את כמות החולים. זה נתון חיובי בהרבה מה-29 שהיינו בו לפני חודש, אבל בגלל הכותרת, הקריאה הראשונית שלי של הגרף היא שקצב ההכפלה עולה – כלומר, יש חוסר הלימה בין הכותרת לבין מה שהגרף באמת אומר.
אני אעשה רגע הפסקה לאמירה כללית יותר, שאולי צריכה לקבל פוסט משלה והצמדה לראשית הבלוג: הרושם הראשוני מכל גרף או אינפוגרפיקה הוא קריטי. בטח ובטח כשמדובר באינפוגרפיקות בעיתון או בפרסומים לקהל הרחב. המסר צריך לעבור באופן ויזואלי ומיידי, או שהוא כושל כאינפוגרפיקה. אם אני צריך להסתכל על הגרף, לבדוק מה השנתות, מה הנתון, ורק אז להבין מה המסר הראשי, הכללי של הגרף, אז הוא לא. גרף. טוב.
אני לא אומר שגרף הוא רק המסר הראשי והמיידי. אני לא אומר שלא צריך להיות את המידע של השנתות והנתונים הנוספים והתובנות הנוספות שאפשר להבין מהגרף. ברור שהם חשובים, והתעמקות בגרף תתן לנו יותר מאשר הגרף הראשי. אבל אם המסר הכולל, ה-high level של הנתונים שלך ניתן לניסוח כ-"קצת ההדבקה ב-16.5 הוא איטי משמעותית מאשר ב-16.4", אבל הגרף שלך מראה גרף שעולה באופן מובהק – הסיפור שלך הולך לאיבוד.
הנה אותו הגרף, רק שהפכתי את כיוון ציר ה-Y כך שהגדלת מס' הימים בהלימה עם ירידת קצב ההכפלה (ותסלחו לי על עריכת הגרף הגסה, אין לי את הנתונים הגולמיים להכין את הגרף מההתחלה):
הנה. גרף שיש הלימה בין הכותרת שלו לבין הסיפור המיידי, הויזואלי שהוא מספר – הקצב יורד. היאח.
השאלה הבאה היא איך בכלל קורה שגרף כזה מגיע לעמוד הראשי של משרד הבריאות, למידע שיוצא לציבור. איך זה שאף אחד לא הסתכל עליו ואמר "רגע, זה הפוך, זה לא אומר מה שזה מתיימר להגיד". וכאן הבעיה, לדעתי, נובעת מהפער בין מי שמפרסם את המידע למי שצורך אותו. אני לא אפידמיולוג, ואני משתדל לא להציק לאפידמיולוגיים עם שאלות בנושא כשכבר יש להם קצת זמן לנוח, אבל אני לא אתפלא אם המדד הזה – מספר הימים הדרושים להכפלה – הוא מדד מקובל ושגור בפיהם. להעלות את המספר הזה זו המטרה, זה היעד. ברור להם שגבוה, במדד הזה, זה טוב, ולשם הם שואפים. אבל זה מה שיכול לגרום, לדעתי, לגרף כזה לצאת לציבור. אבל לציבור אין את ההתניה הזו שגבוה=טוב במדד ההכפלה, שהוא בכלל לא מדד הכפלה אלא מדד זמן בין הכפלות, ולכן הגרף הזה בעצם פונה לקהל של אפידמיולוגים, ולא לקהל הרחב. וזו טעות שרבים עושים, כשלא מבינים באמת את הפער בין מה שהמומחים מבינים, לבין הקהל שאליו מנגישים את המידע.
מה אהבתי בגרף הזה? שהעיוות בו סובטילי ולא קופץ מיד לעין, בניגוד לגרפים גרועים אחרים. מצאתם כבר את הבעיה? היא בציר ה-Y של הגרף הזה, שבמגוון גרפי ההידבקות הרבים (רבים, רבים) שאנחנו נחשפים אליהם יכול להיות ציר לינארי (כלומר, שהקפיצות של השנתות הן בגדלים קבועים, נגיד 10, 20, 30) או לוגריתימי (כלומר, שהקפיצות גדלות באופן אחיד, נגיד 10, 100, 1000). לשני סוגי הצירים יש שימוש שונה – הראשון יעביר את סדרי הגודל של כמות הנדבקים, השני יעביר את סדר הגודל של *קצב הגידול* בשינוי.
הגרף הזה, עם זאת, הוא… לא זה ולא זה. כלומר, הוא *כמעט* לינארי. והוא *נראה* כמו לינארי, אבל המרווחים בין השנתות לא קבועים. יש לנו 30, 60 ו-90 (קפיצה אחידה של 30), אבל אז פתאום… 100? קפיצה של 10 בלבד? מה המשמעות שלה? תאורטית, שינוי כזה יכול לייצר גרף עם קפיצה גדולה באופן מלאכותי – הקפיצה מ-60 ל-90 ומ-90 ל-100 תיוצג באותו גובה של הגרף וזה יכול ליצור תחושת גידול מזויפת. אבל במקרה הזה מיד חוזרים לקפיצות של 30… עד 190 שם יש קפיצה של 50, ואז שוב 10, ומשם קפיצות בגודל של 50.
אז למה זה טוב? זה ממש לא ברור. אם באמת היתה כוונה לייצר גרף שמעביר סיפור שונה מהנתונים האמיתיים, היה צריך לעשות את זה אחר לגמרי – כי הסיפור שהגרף הזה מספר הוא, בסופו של דבר, לא מאד שונה מגרף שבאמת מתואם עם ציר לינארי אחיד, כפי שמיד פורסם בטוויטר כתגובה לגרף הזה:
אולי הקפיצה בסביבות ה-200 נועדה להדגיש את הצניחה ב-29 למרץ? להדגיש את העליה ב-21 למרץ? לא ברור. אין כאן סיפור שעולה מהשינויים הללו. יכול להיות שכאן, כמו במקרים רבים בעבר, פשוט לקח עורך כלשהו את הגרף הראשוני שצויר ע"פ הנתונים, החליט שהוא לא מספיק יפה, חלק או אלגנטי, והלך ועשה בו שינויים משיקולים אסתטיים. ולעזאזל הסיפור של הנתונים.