לא כל יום אני יכול להגיד שנתקלתי בשני גרפים שונים שהוציאו ממני תגובה פיזית לא רצונית ומלמול של "מה לעזאזל?!". אבל אתמול בהחלט היה יום כזה, בזכות הגרפים ששלחו לי הדס ושי (תודה, הדס ושי!), גרפים שמראים באמת עד כמה נמוך אפשר לרדת עם התעלמות מוחלטת – או, אולי, מכוונת – מאחד המרכיבים הבסיסיים בכל גרף, והוא מערכת הצירים. בפוסט הזה נתמקד בגרף הראשון שמתעלם באלגנטיות מציר ה-Y, ובמקביל יתפרסם פוסט נוסף על התעלמות מציר ה-X.
לפוסט השני: מאיזה ציר נתעלם היום? ציר ה-X.
הגרף הזה פורסם ב-Ynet, בתוך כתבה ארוכה על בצלאל סמוטריץ', שר התחבורה היוצא, ופועלו במשרד. הכתבה לוותה באינפוגרפיקה הזו, אם אפשר לקרוא לה ככה, ואני בטוח שתוכלו בקלות להבין מה הבעיה איתה:
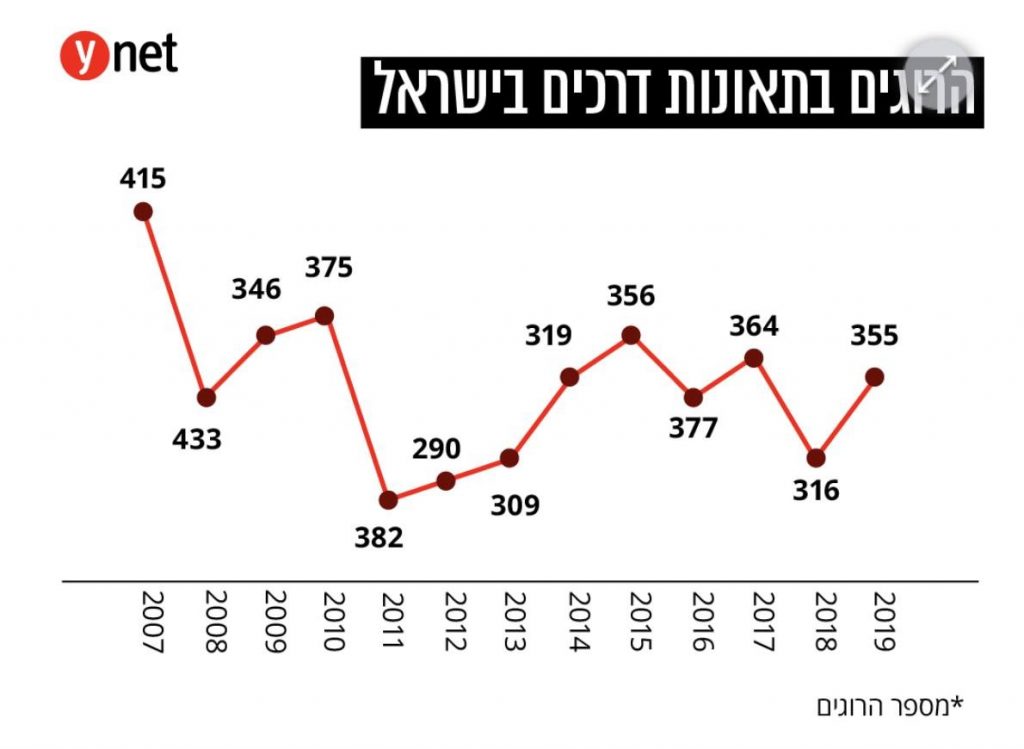
הרמז הראשון שעומדת להיות בעיה היא שבניגוד לציר ה-X (השנים), לא מסומן ציר Y על הגרף. אבל זה לא נורא, נכון? הרבה פעמים ציר ה-Y הוא implicit וקל להבין אותו מהנתונים. מה… רגע. מה קורה פה? אנחנו מתחילים ב-415, אבל אז יורדים ל-433. אולי ציר ה-Y יורד, משום מה? לא, זה לא הגיוני, כי אחרי שעלינו חזרה ל-346 (שנמצא בין 415 ל-433 מבחינת הגובה), אנחנו עולים ל-375. כלומר אין שום קשר בין העליות והירידות של הגרף לבין הנתונים שמוצגים בו. המספר הגבוה ביותר הוא 433, אבל הוא בערך האמצעי מבחינת הגובה בגרף. הנקודה הנמוכה ביותר, זו של 382, היא בין הגבוהות ביותר מבחינת הנתון. מה קורה כאן?
אז פניתי לחברי הטוב אקסל (או, לשם הדיוק, חברי הטוב החדש Google Sheets, פשוט בגלל שהמחשב החדש שלי מריץ לינוקס ואין לי אופיס), וזה מה שהנתונים יצרו לי:
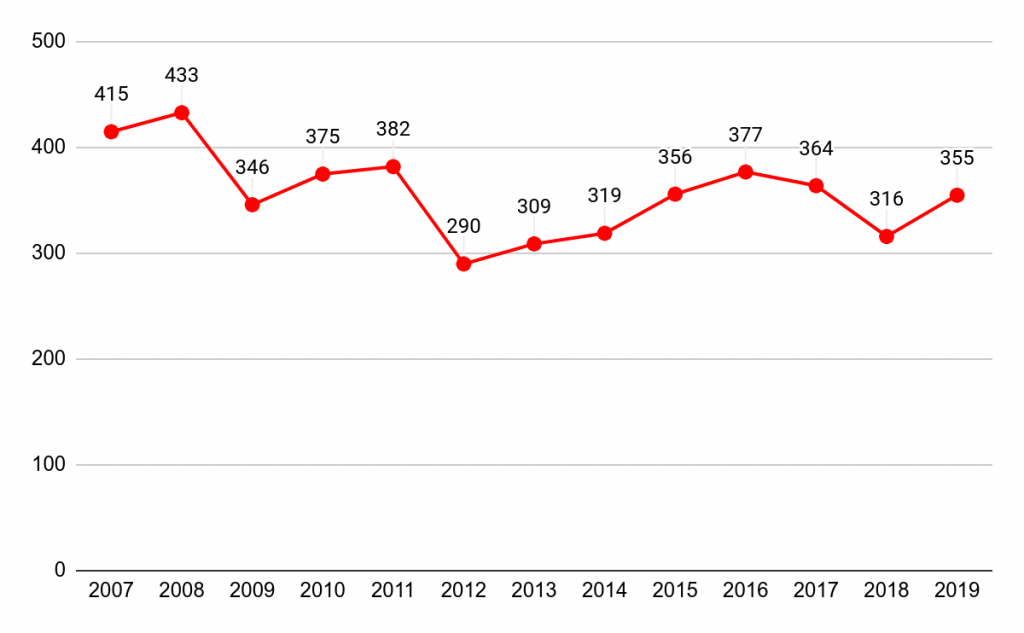
גרף שטוח בהרבה, פחות דרמטי, ועם עליות וירידות במקומות הנכונים(!). זה גרף הרבה פחות מעניין, אפילו אם היינו מקצצים את בסיס ציר ה-Y. אבל המשכתי לתהות מה היה יכול לגרום ל-ynet לפרסם את הגרף הזה. אבל אז, אחרי קצת משחקים עם הפרמטרים של הגרף, הגעתי למשהו מעניין:
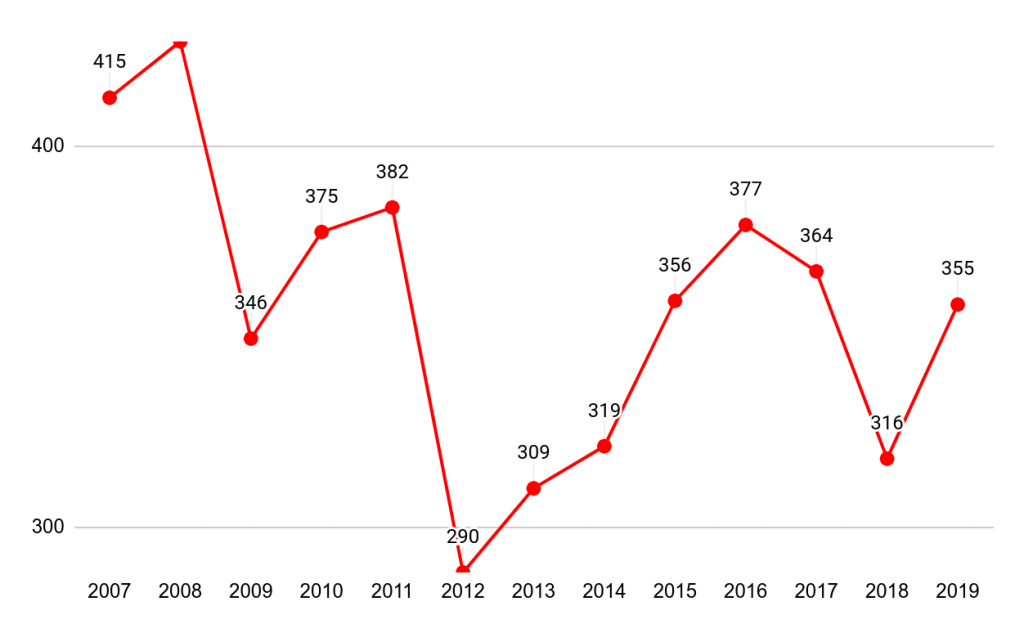
היי, מה זה פה? יש כאן את הצורה של הגרף של ynet, פחות או יותר! אולי הגרף כן הגיע מהנתונים, למרות הכל? מה קורה פה?
אז מה שקרה הוא שאני הגדרתי לגרף שציר ה-Y לא יהיה לינארי, אלא לוגריתמי. כלומר שבמקום להראות שינויים פשוטים במס' המתים בתאונות דרכים, הפכו אותו לגרף שמראה שינויים בקצב העליה או הירידה בתמותה. הבעיה היא שבניגוד לגרף הידבקות בקורונה, שאליו קישרתי כאן בתחילת הפיסקה, אין הגיון בגרף לוגריתמי אם אין לנו רצון להציג איך הקצב משתנה. זה חשוב כדי לעקוב אחרי התפשטות של מגיפה. פחות בשביל נתון עם תנודות קטנות יחסית ולא מצטברות, כמו תאונות דרכים.
אבל זה רק מסביר איך אפשר להגיע מהנתונים לצורה הזו של הגרף. איך זה מסביר את הירידות במקום העליות? ובכן, ככל הנראה מה שקרה הוא שבגרף של ויינט פשוט קיצצו, באגביות, נתונים שלא התאימו להם, והזיזו נתונים אחרים למקום שלהם בגרף. נקודת ההתחלה של ויינט? הגבוהה ביותר בגרף? היא מתאימה דווקא ל-datapoint השני, זה של 2008, שבו באמת היה את מס' ההרוגים הגבוה ביותר (ושבגרף שלי משום מה קוצץ בשולי הגרף, אבל לא נורא, עדיין מובן). אבל כנראה שהעורך היה מעוניין בגרף שמתחיל הכי גבוה שלו ומשם יורד, בין אם על מנת להעביר מסר מסוים, או כי זה נראה טוב יותר. בכל מקרה, זה גרם לכל הגרף לזוז הצידה על ציר ה-X, ולכל הנתונים להיות מפוספסים לחלוטין. אבל אם אנחנו מניחים שיש עוד נקודה מצד שמאל שבה מתחילים הנתונים, פתאום הכל יותר הגיוני. העליה מ-346 ל-375 היא מה שבגרף כתוב מ-433 ל-346. ואז יש לנו ירידה מתונה יותר ל-382 (הגיוני!), צניחה ל-290 – הכל פתאום מסתדר הרבה יותר טוב.
ומה לגבי ynet? אני לא יודע אם השינוי הזה נעשה בכוונה או בטעות, מתוך מטרה להטעות או חוסר הבנה של הכלי. מה שאני יודע הוא ש-24 שעות אחרי שראיתי את הגרף, הוא כבר לא נמצא בכתבה. הוא לא הוחלף בגרף טוב יותר. הוא פשוט כבר לא שם.