הקורא יובל הפנה אותי לכתבה הזו בויינט, על הרגלי המשפחתיות הישראלים:
סקר: כמה פעמים בחודש ישראלים נפגשים עם הסבתא?
ובו שני גרפים מרתקים:
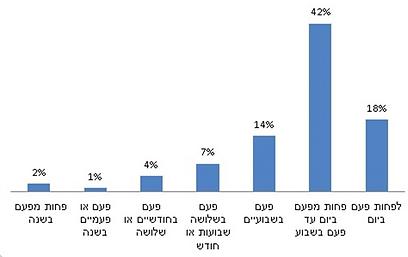
זה הראשון, המציג את תכיפות הפגישות של סבים וסבתות עם נכדיהם. הוא יחסית פשוט וברור, בלי משחקי פיקסלים וסדרי גודל, אבל זה לא משנה את העובדה שכשאנחנו סוכמים את כל העמודות, אנחנו נשארים עם 88% בלבד. אני לא יודע אם המשמעות היא שה-12% הנותרים לא ענו על השאלה (ואם כך, למה לא להוציא אותם מתוך השקלול בכלל?) או שהיו עוד תשובות אפשריות (למרות שתשובות הקצה כאן הן פתוחות), או שסתם מישהו זרק מספרים, אבל ל-100% זה לא מגיע.
ובכיוון השני, יש לנו את העוגה הזו, לאופי הפעילויות המשותפות:
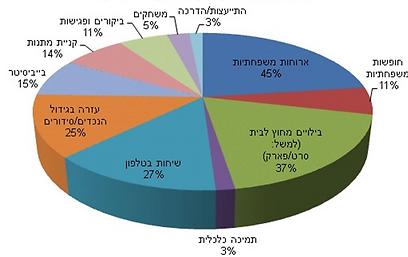
שוב, בלי יותר מדי מניפולציות (חוץ מההטיה הבסיסית של עוגה תלת מימדית). למען האמת, זה נראה כמו גרף שיצא ישירות מאקסל (גרסאות 2003-2010, לפחות). אבל שוב, אם נסכום את כלל האחוזים בהתפלגות, נגיע ל-196% מלאים! כמעט פי שתיים מהאנשים שבעצם היו בסקר!
במקרה כאן, אני חושב שהבעיה היא בהתאמה בין סוג הויזואליזציה לבין סוג הנתונים. גרף עוגה נועד להראות התפלגות מתוך שלם, אבל לא מדובר כאן, כמו בגרף הראשון, על אפשרויות שמהן אפשר לבחור רק אחת. אני מניח שהמשיבים יכלו לתת יותר מתשובה אחת – גם שיחות טלפון, גם בילויים, גם ארוחות – וכך נוצר מצב שהיו יותר תשובות מאשר משיבים. כנתון, זה הגיוני לחלוטין. כגרף עוגה? מפספס את הנקודה.
מה שהייתי עושה כאן הוא פשוט להחליף את הייצוגים הויזואליים של שני הגרפים. את הראשון, שאכן מציג התפלגות של בחירות חד-ערכיות מתוך רשימה, הייתי מציג כעוגה. ואת השני, שמראה את הפופולריות היחסיות של אפשרויות שונות בלי קשר למכלול, הייתי מציג בגרף עמודות:

